齊藤 剛史 研究室
九州工業大学 大学院情報工学研究院 知能情報工学研究系
スマートデバイスを用いた
発話シーンデータベース(SSSD)
SSSDとは?
SSSDは、九州工業大学齊藤剛史研究室で構築した、スマートデバイスを用いた発話シーンデータベース(Speech Scene database by Smart Device)の略で、読唇研究向けの公開データベースです。
話者がスマートデバイスのインカメラを利用して、話者自身で撮影した発話シーンを収録しています。話者はスマートデバイスを手で持つ、壁に掛ける、あるいは机に置く、で撮影しています。撮影場所は、大学の研究室や講義室、自宅、自動車内などで撮影しています。話者は発声している場合だけでなく、小声、あるいは発声せずに発話しているシーンもあります。
News
- 2019年5月17日(金):LF-ROIを用いた3D-CNNによる認識プログラムを公開しました。こちらをご覧ください。
- 2019年5月15日(水):全データベースを更新しました。話者数およびサンプル数を変更しました。
- 話者数を36名→72名に追加しました。
- サンプル数を30サンプル→10サンプルに減らしました。
- 顔特徴点検出をOpenPoseの顔特徴点検出機能からdlibのshape_predictorに変更しました。これに伴い特徴点数は70点→68点に変わりました。
- 2018年7月31日(火):LF-ROIにおいてs32_018_001の00046.jpgファイルが不足していました。s32.zipファイルを更新しました。
- 2018年5月22日(火):コンペティション「機械読唇チャレンジ」(第5回サイレント音声認識ワークショップ)用の5,000テストデータを公開しました。
- 2018年4月8日(日):本データベースを公開しました。
SSSDの詳細
- 発話内容:日本語25単語
# 発話内容 # 発話内容 # 発話内容 0 ぜろ 10 ありがとう 20 どういたしまして 1 いち 11 いいえ 21 はい 2 に 12 おはよう 22 はじめまして 3 さん 13 おめでとう 23 またね 4 よん 14 おやすみ 24 もしもし 5 ご 15 ごめんなさい 6 ろく 16 こんにちわ 7 なな 17 こんばんわ 8 はち 18 さようなら 9 きゅう 19 すみません
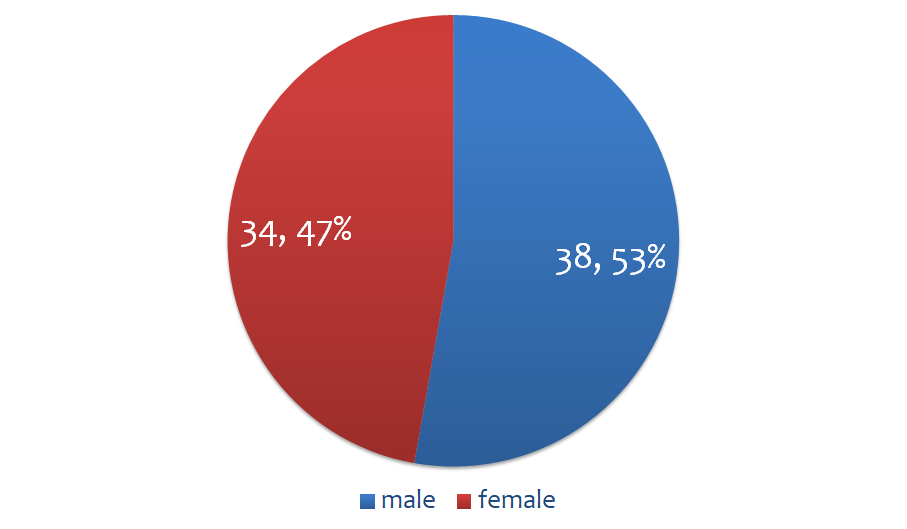
- 発話者数:72名(男性38名、女性34名)
- 性別分布
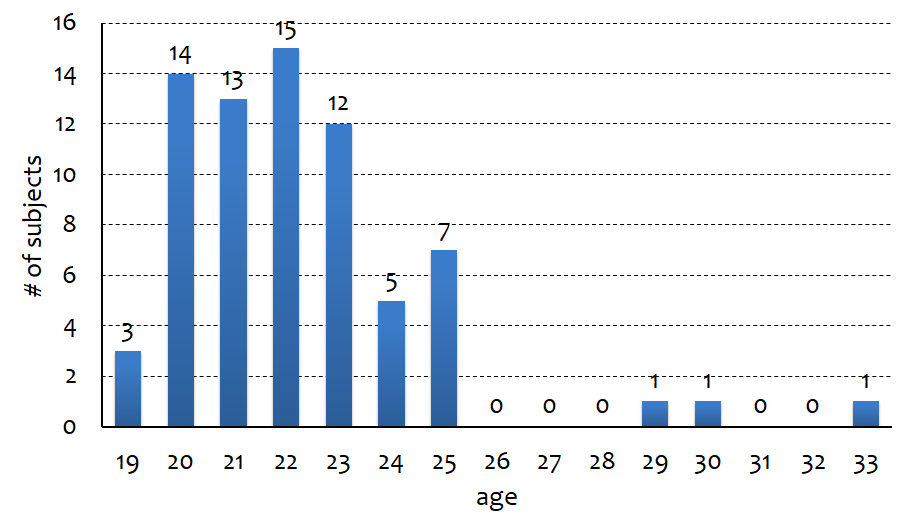
- 年齢分布
- 性別分布
- 提供データ
- 72名(男性38名、女性34名) × 25単語 × 10発話 = 18,000発話
- 顔下半分画像LF-ROIのフレーム画像(画像サイズ:300×300画素、jpeg形式)
- 動画像形式ではありません。フォルダに発話シーン単位で格納されています。
- フレーム画像のファイル名は1から始まる5桁の通し番号(%05d.jpg)の形式ですが、顔検出に失敗により抜けているフレーム画像もあります。
- 話者12名(3,000発話)単位でzip形式でまとめてあります。一つのzipファイル容量は約1名あたり約3GB、72名分で約20GBです。

下図はs010_011_007(話者s010の単語011「ありがとう」の発話シーン)のLF-ROIフレーム画像をgifアニメに変換したものです。

サンプル:s010_011_007.zip(約1.83MB)話者s010の単語011「ありがとう」の発話シーン - 顔特徴点座標(68点のx-y座標、csv形式)
全話者(72名)をzip形式でまとめてあります。ファイル容量は約259MBです。
サンプル:s010_011_007.csv(約36kB)話者s010の単語011「ありがとう」の発話シーン - 音声データ:なし
- LF-ROIと顔特徴点座標の関係
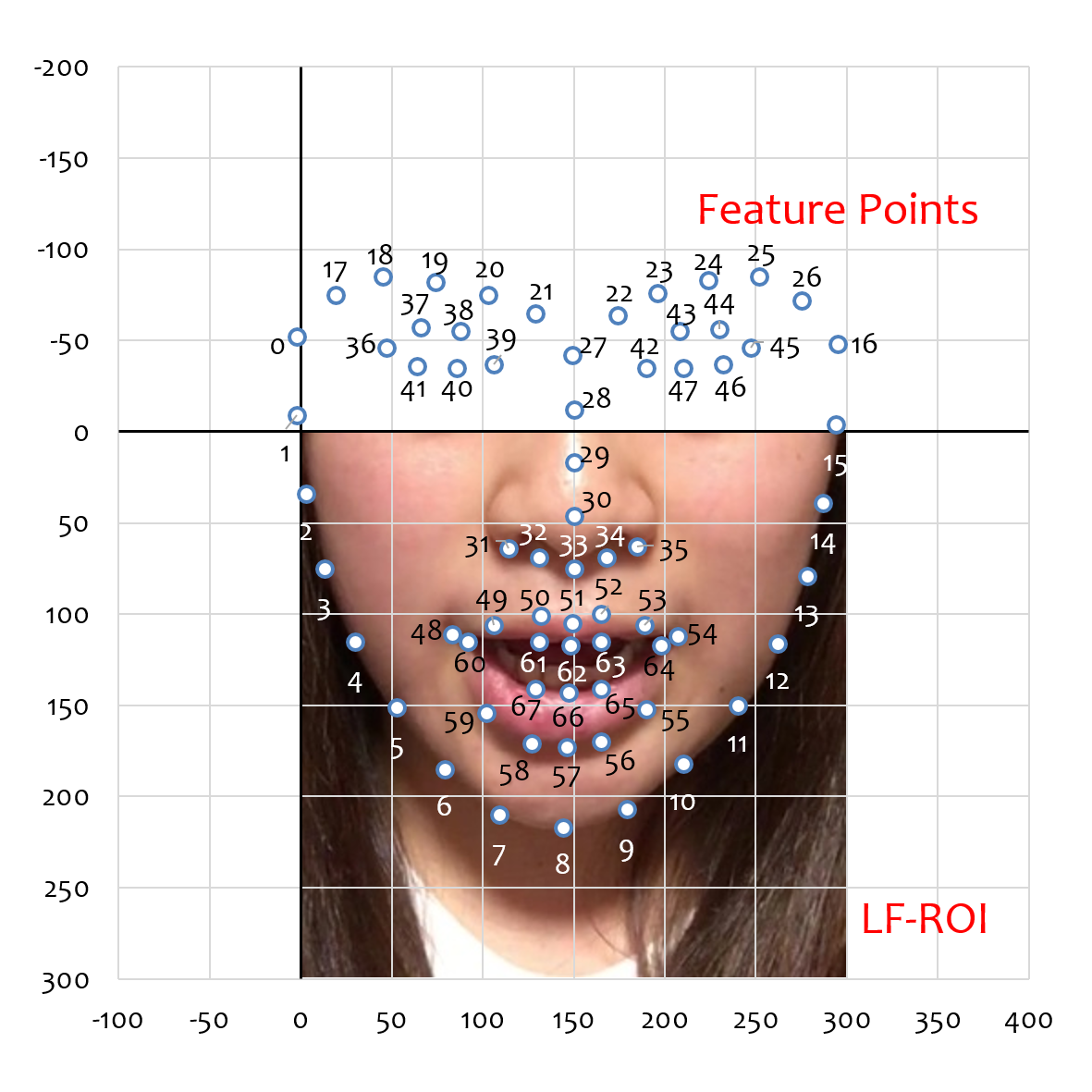
- 提供データの前処理(LF-ROIの抽出方法など)については、論文[1][2]を参考にして下さい。
- データリスト(18,000分)
- ・LF-ROIフォルダのリスト
- ・CSVファイルのリスト
- ※リストファイルは、1列目にCSVファイル名(あるいはLF-ROIフォルダ名)、2列目に正解単語番号(0~24)が記されています。
- その他:提供データは2019年5月15日時点のものです。今後、提供データの内容が変更する可能性もあります。
- 72名(男性38名、女性34名) × 25単語 × 10発話 = 18,000発話
- 撮影機器:スマートデバイス(Apple iPad Pro、各種スマートフォン)
- フレームレート:30fps
- 利用範囲:研究に限ります。改変や再配布等は禁止します。
- 公開日:2018年4月8日
- 価格:無償
- 配布方法:利用契約書に記入し、下記お問い合わせ先にFAXあるいはメール(記入済み利用契約書をスキャンして、pdf形式あるいはjpeg形式で保存してメール添付)で利用契約書を提出して下さい。利用契約書を受理した後、配布方法をメールで連絡します。データは外部クラウドストレージで管理しています。ストレージへアクセスするために、利用契約書に記入していただいたメールアドレスを登録します。
- ご利用の際には以下の論文を引用して下さい。
- [1] 齊藤 剛史, 窪川 美智子: SSSD:スマートデバイスを用いた読唇技術向け日本語データベース, 電子情報通信学会技術研究報告, vol.117, no.513, pp.163-168, 2018.
- [2] Takeshi Saitoh, Michiko Kubokawa: SSSD: Speech Scene Database by Smart Device for Visual Speech Recognition, Proc. of ICPR2018, pp.3228-3232, 2018.
- お問い合わせ先:
九州工業大学 大学院情報工学研究院 齊藤剛史
E-mail:saitoh at ai.kyutech.ac.jp
FAX:0948-29-7713 - 本研究の一部は、JSPS科研費16H03211および平成28年度文部科学省地域イノベーション・エコシステム形成プログラム「IoTによるアクティブシニア活躍都市基盤開発事業」の助成によるものです。